Overhead in Packet Networks
by Richard Hay
![]()
Network overhead is an important
concept to understand. Understanding
overhead is basic to understanding the methodology employed by various
technologies to get information from one place to another, and the costs
involved. This paper will cover the
basics of overhead affiliated with Ethernet, ATM, Frame-Relay, POS, and
SONET. Similar information can be found
on FDDI, Token Ring, and other technologies, but will not be covered here.
Basic Terminology
BPS
- Bits per second (1 Kbps = 1000, 1 Mbps = 1000000, and 1 Gbps = 1000000000)
PPS
- Packets per second
PCR
- Peak Cell Rate
Byte
- 8 bits
Packet/Frame/Cell
- terms that refer to discrete data units from different technologies
Layer2
– Refers to the Data/Link Layer of the OSI Network Model
Layer3
– Refers to the Network Layer olf the OSI Network Model
Life of a Data Packet
In
this document, TCP/IP will be assumed to be the protocol being utilized for
packet data. Much of the world’s
telecommunication networks are forwarding IP packets to and fro at this very
moment. During the course of an IP
packet’s journey from a transmitter to a receiver, it is encapsulated and
de-encapsulated into and out of framing headers and trailers that define how
the packet will make it’s way to the next hop in the
path. This paper is designed to explain
what happens when a packet arrives at a router or a switch, is processed, and
then forwarded to the next router or switch.
Ethernet
IEEE
802.3 Ethernet, the world's most popular LAN technology, is not going anywhere.
It is widely used in 10 Mbps, 100, Mbps, and 1000 Mbps (also called Gigabit
Ethernet) varieties. This technology for
framing bits can be supported by many types of physical media (Copper wires,
Fiber-Optics, Wireless, Coax). These facts are commonly known. But here are things that are not always
obvious. Ethernet Frames can range in
size from 64 bytes (512 bits) up to 1518 bytes (12144 bits) in size. And they look like this:

Now
what is not shown above is the space between packets that cannot be used. This space is usually mandated to be at least
20 bytes. That means that for each
packet on the wire, there are at least 20 bytes you cannot use. I will not leave that statement unsupported
of course, because that would be mean.
In the specification for Ethernet (and this is true for 10/100 and
GigaBit Ethernet), it states that no less than 96 bits shall be between each
packet and is called 'Interpacket Gap'.
Now for you mathematicians out there, this is only 12 bytes. What about the other 8? Well, preceding each ethernet packet is an 8
byte preamble that heralds the arrival of the packet. It is not part of the packet. It just announces that a packet is
forthcoming. So the 12 bytes of
interpacket gap and 8 bytes of preamble are space between packets that cannot
be used. This means, in effect, that
when a 64 byte Ethernet frame is sent, 84 bytes are actually allocated for the
transmission of the frame. This is not
obvious. But it is the truth.
Okay, I know what you are asking. Why? I
mean, the preamble can be understood easily enough, but why waste 12 perfectly
good bytes between packets? Why does the
specification require that these bytes be sacrificed and give pause to the
continuous stream of packets? The
culprit in this case is the ethernet hub.
Specifically, a hub that has a number of RJ-45 Ethernet ports used to
interconnect machines using Category 5 UTP Copper cabling (often called Twisted pair). These
hubs became popular for a great number of reasons. Put simply, the star topology created by the
hub made it so that if there was a disconnect in the
network, it typically only effected the single connection between the hub and
that one station allowing everyone else to continue communicating unaffected. Believe me, this beat the crap out of the
'christmas tree light' topology of networking that was a part of the
alternatives (one link goes out and the entire network is dead). However, a hub transmits a
lots of packets all together, and there is a good chance that there will
be collisions that will require a packet to be retransmitted. And if a specific client is trying to
converse with a server, and is sending it's ethernet packets with no gap, it
prevents other clients from being able to communicate with the server
simultaneously. Simple client-server
networking is responsible for the mandated ethernet gap. Let someone else talk every now and then. You have two ears and one mouth and so
on. Now there is a question to why you
would continue to use this gap on Gigabit Ethernet when this problem no longer
exists (Now switches allow for much greater volume without collisions). Ever seen a Gigabit Ethernet Hub? Do you think you ever will? Never. The reason the interpacket gap continues to
be supported on higher bandwidth interfaces is because they did not want to
change the standard. Nostalgia.
Examples
Okay,
now I will spell out some examples of the overhead incurred when using ethernet
packets to transmit your data.
Say
I was sending data using nothing but 64 byte ethernet frames. As we will see this would be extraordinarily
inefficient. But this a fantasy land, so
we can do it. Lets
say I was using a 100 Mbps Ethernet Connection.
Lets do the math.
100 Mbps = 100000000 bits per second
How many packets can I send? The answer is 148809.5, and I will explain why. The equation to convert from BPS to PPS is as follows.
PPS x Frame Size x 8 (to convert the units from bytes to bits) = BPS
148809.5 x 64 x 8 = 76190464 bits per second
76190464 is not equal to 100000000. This is because we must do another equation to figure out the amount of bits that are being allocated to the interpacket gap and preamble. For each of the 148809 packets there are 20 bytes we cannot use. So the overhead for this situation would be this:
148809.5 x 20 x 8 = 23809520 bits per second that we cannot use
And
76190464 + 23809520 = 99999984 bits per second which is right at
the 100000000 we can use
So
the overhead incurred by the gap and preamble in this case is 23.8% or the
total bandwidth of the link. In
addition, there is additional overhead inside the ethernet packet itself. In 64 byte ethernet frames, only 46 bytes are
actually available for an IP packet. So
of the 84 bytes needed to transmit a 64 byte ethernet frame with an IP packet
inside, only 46 bytes is the actual IP packet.
38 bytes are consumed in overhead.
That means only 54.76% of the bits are the IP packets that I want to
relay from one point to another. Over
45% of my connection is consumed by overhead.
However, this is an extreme condition, and is not the norm. This is because The
larger the packets are, and ethernet allows for sending variable length frames,
the fewer of them it takes to fill the pipe.
The fewer frames, the fewer gaps, the fewer preambles,
and, thus, the less overhead that is incurred. Big frames are more efficient than small
ones. So ethernet overhead is a function
of the packet distribution that is on a network at any given time. Depending on whose packet distribution you
are looking at, the average Internet packet size is somewhere between 230-260
bytes. The biggest reason that the
frames tend to be closer to the smaller end of the available range is that
usually about a 3rd of all the packets are the smallest sizes. This is because people like to use TCP/IP for
networking. And TCP/IP, as explained by
Vint Cerf once (and he wrote the protocol), is like sending a novel to your
grandmother through the mail using postcards.
You send a few hundred postcards with your address and hers on the card,
along with a number so she can put them in order when she gets them, and a bit of the story on each one. Now, in reality, TCP requires the constant
sending of acknowledgments that all the packets have made it from the sender to
the receiver as a part of the session.
It is these acknowledgments that create over 30% of bandwidth being used
as the smallest frames. Anyway, day the
distribution displays that the average packet size is about 256 bytes or so.
That would change the equation to read like this (still using 100 Mbps
ethernet):
PPS
x Frame Size x 8 = BPS
45289.9
x 256 x 8 = 92753715 bits per second
And
don't forget the gap and preambles
45289.9
x 20 x 8 = 7246384 bits per second
92753715
+ 7246384 = 100000099 (a bit over, but right at theoretical line rate)
So
considering an average frame size of 256 bytes, of which 238 is the IP packet
within, 238 out of every 276 bytes on the wire is IP packets. That comes out to a ratio of 86.23% of the
bandwidth is payload, and about 13.77% is required for overhead. That is a much better ratio that the previous
example. Much more
realistic too. If all of your
ethernet traffic were 1518 byte packets (also not realistic, and as most of us
use TCP/IP – impossible), then 97.5% of the bandwidth would be payload and only
2.5% would be overhead. So it is evident
that ethernet overhead varies and is a function of packet distribution. The more smaller
packets you have, the less efficient ethernet will be. And the when the network tends to have more larger packets, the more efficient it is. With applications like Voice over IP and
Streaming Video over IP, the packet distributions could be heading lower. Ethernet may not be the world’s most
efficient networking technology, but as long as I can go buy a 100 Mbps Network
Interface Card for $15, it is dirt cheap.
And Ethernet has varieties of 10/100/1000 Mbps, soon to be 10000 Mbps.
ATM
For this discussion we will focus on
ATM overhead as it relates to transmitting packets. Data over ATM,
multiprotocol over ATM, AAL5, RFC1483, and so on. These all describe the same
circumstance. That being the situation
of taking variable length packets and inserting them into fixed sized ATM
cells. This process is called
Segmentation and Reassembly (SAR) for obvious reasons. Perhaps it would be best if the structure of
an ATM cell is displayed.
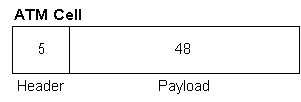
And
that is how every ATM cell looks. Each
cell is 53 bytes. Each one has a 5 byte
header and a 48 byte payload. There is
no gap or flag delimiter between cells.
There is no need. All cells are
simply sent in a continuous string. ATM
switches can process this stream because the size of the cells is a fixed and
known value. Now, right away, you can
see that 5 bytes out of every 53 are overhead.
That is an automatic 9.5% right off the top. Ah, but there is more waste when taking
packets and slicing them into ATM cells.
If a packet is sent that has a 500 byte IP packet
inside. ATM switches implement various
standards (usually RFC 1483) to create what is commonly called a Protocol Data
Unit (PDU). A PDU is a group of cells
that have in common the fact that they are all carrying a piece of the 500 byte
IP packet. It won’t fit in one cell
after all. In the first cell of the PDU,
the packet is preceded by an 8 byte header that defines which type of
encapsulation is being used to wrap the packet in. Common types are AAL5 SNAP, VCMux, LLC, VCMux
PPP, and Classical IP. There are a
number of encapsulations that can be used but they all do essentially the same
thing. They put a header in front of the
500 byte packet (usually 8 bytes in length), and an AAL5 trailer at the end of
the packet to declare that the PDU is complete.
So in this case, a 500 byte IP packet would be wrapped in an 8 byte
header, and 8 byte trailer, and become a 516 byte PDU. This needs to be sliced into 48 byte pieces,
and, it becomes obvious that 11 cells will be required to transport this
PDU. That means that 583 bytes will be
sent to transport this 500 byte IP packet.
That comes down to a ratio of about 85.75% payload, and 14.25%
overhead. Not too shabby. Say we used the ballpark average frame size
of a 238 byte IP packet. When divided by
48, it is clear that 6 cells would be required to transmit this PDU:
(238
+16)/48 = 5.2916
Now
here is an important point. If even a
single byte overlaps into another cell, that cell is required to assist in
transmitting the PDU. Even
though 47 of the 48 byte payload is just filler. This makes for varying
degrees of efficiency. For example, 3 cells can move 144 bytes in payload (48 x
3). Minus the 16 bytes in PDU header and
trailer that means a 128 byte IP packet fits perfectly into 3 cells. So it would take 159 bytes (53 x 3) to
transmit a PDU with a 128 byte IP packet inside. That reflects an 80.5% payload to 19.5%
overhead ratio. But say the packet is 129 bytes. This will be much less efficient. If the IP packet is 129 bytes, the resulting
PDU will be 145 bytes, and it will overlap into the 4th cell. Now, 212 bytes (53 x 4) are required to
transmit the PDU, of which 129 bytes are the IP packet, which dramatically
reduces the ratio to 60.8% payload and 39.2% overhead. That is a 20% difference in overhead incurred
resulting from the packet size being just a single byte larger. The point here
is simple. The amount of overhead once
again depends on the packet distribution.
But it is not as simple as the “small packets = inefficient, big packets
= efficient” equation you get with ethernet.
Rather, the efficiency of ATM for transporting data packets varies as
the ratios between IP packet payload, number of cells, and amount of bytes
wasted in cell padding shift. However,
it is a good bet that 15 – 20% of bandwidth ends up being sucked up in overhead. Normally with ATM, it is good enough to
understand the ballpark range of what is being sacrificed in choosing to use it
as the transmitting technology. Here is an example of a data packet going out
of a cleint into an ATM cloud:
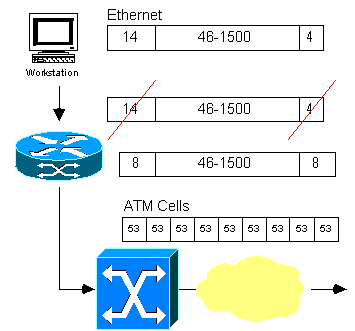
In
the spirit of ‘a picture is worth 1000 words’, the figure displays an IP
packet, ranging size from 46-1500 bytes being encapsulated in an Ethernet frame
to get to a router. Once there, the
ethernet encapsulation is striped off, leaving just the IP packet. Then this is wrapped inside of a PDU
encapsulation for transmission out to an ATM switch. Then it is sliced into the 48 byte payloads
of 53 byte ATM cells. And out it goes.
Frame-Relay
Frame-Relay Data Rates
|
Interface |
Data Rate |
|
|
|
|
DS-0 |
64Kbps |
|
DS-1 |
1.544 Mbps |
|
DS-3 |
44.736 Mbps |
Frame-Relay is one of the world’s most deployed
Wide-Area Network technologies. It is
really a descendant of the X.25 protocol.
The speeds range from 64K DS-0 channels up to 44.736 Mbps DS-3 connections. The most well known speed is probably the
DS-1 speed (also called T-1) of 1.544 Mbps.
In the classic days of data networks, much of the cable spanning long
distances was set up for analog transmission. Analog transmissions are very noisy. So X.25
checked the packet integrity of each frame at each and every switch to verify
it negotiated the analog connection properly.
Upon the development of digital transmission, the lines were cleaned up
dramatically, and it was no longer was necessary to check packet integrity at
every hop (which added seconds of latency).
So you could say that Frame-Relay is a stripped down version of X.25
without all of the error checking. And
the frames look like this:
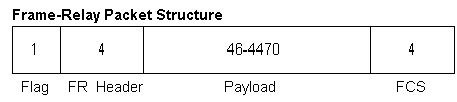
The payload can be larger than
ethernet frames, but often the payload is less than 1500 since the IP packets,
which end up on a Frame-Relay connection, originated from an ethernet LAN. Now the 1 byte Flag is the delimiter between
packets. Frame-Relay needs this
delimiter so that a switch can determine when a new packet begins, since this
is another variable length datagram technology.
Going back to the example of an
average IP Packet of 238 bytes, it is clear that Frame-Relay would require 247
bytes (238 + 9) to transmit that frame.
This is an excellent ratio of 96.35% payload to 3.65% overhead. Now if the IP packet is 46 bytes, Frame-Relay
needs 55 bytes to transmit it, and the ratio, at its worst, is 83.6% payload to
16.4% overhead. At best, when the frames are 4400 bytes in size, over
99.7% of the bandwidth is payload and less than half a percent is required for
overhead. The smaller the frames, the
less efficient, the bigger the frames, the more efficient.
SONET
Table 1.0
|
Interface |
Data Rate |
Without SONET
Overhead |
|
|
|
|
|
OC-3 |
155.52 Mbps |
149.76 Mbps |
|
OC-12 |
622.08 Mbps |
599.04 Mbps |
|
OC-48 |
2.488 Gbps |
2.396 Gbps |
|
OC-192 |
9.953 Gbps |
9.585 Gbps |
|
OC-768 |
39.813 Gbps |
38.339 Gbps |
The above table reflects the optical
speeds of SONET Interfaces. The last
column reflects the payload bandwidth minus the 3.7% overhead required for
layer 1 SONET overhead. SONET overhead
is the same 3.7% all the time. It is
consistent for OC-3, OC-12, OC-48, OC-192, and so on. And this reflects the
overhead required for SONET Section, Line, and Path encapsulation of it's
Synchronous Payload Envelopes (SPE) in which data in transferred. So overhead for SONET is easy. It's always 3.7%. This overhead is incurred whenever SONET is
the optical technology being used for transmission (true for ATM over SONET
Optical Interfaces, and Packet over SONET Optical Interfaces).
Packet over SONET (POS)

RFC 1619 says it all, but here it is again
anyway. That RFC is entitled 'PPP over
SONET/SDH', and that is very apropos.
But POS interfaces can also support HDLC encapsulated packets over
SONET, and also Frame-Relay encapsulated packets over SONET. Fortunately, the overhead associated with
each of these encapsulations is identical. The only thing that varies is the
size of the checksum (FCS). Typically,
POS interfaces allow you to choose between a 16 and a 32 bit checksum (either 2
or 4 bytes trailing the packet and being checked to verify transmission
integrity). The 4 byte header and 1 byte
flag delimiter is the same for PPP, HDLC, and Frame-Relay over SONET. And the engineer chooses to use 2 or 4 byte
FCS sizes.
That means that, once again, as the overhead is
incurred on a per-packet basis, the smaller the packets, the more of them there
are, the more overhead. The bigger the
frames, the fewer there are, the less overhead is required to send them. This pretty much holds true for any
technology that supports variable length frames.
Going back to the example of the 238 byte IP packet,
POS needs either 245 or 247 bytes to transmit the datagrams (depending on
whether 16 or 32 bits FCS is selected).
Often 32 bits checksums are chosen as they tend to be more
accurate. Anyway, assuming a 32 bit
checksum, the average POS overhead ratio would be 96.35% payload to 3.65%
overhead. So POS tends to be more
efficient than ATM or Ethernet for transmitting data packets. And it scales to much higher speeds than
Frame-Relay. If your main concern is
transmitting data traffic, POS is almost always the best choice. Unless Gigabit ethernet interfaces cost about
the same as an OC-12. Even at its least
efficient, a Gigabit Ethernet interface carries more payload than a POS
OC-12. And if the average payload ratio
is around 85% payload to 15% overhead for ethernet, then a Gigabit Ethernet
interface will carry about 850 Mbps in payload, which far exceeds the 600 Mbps
an OC-12 is capable of. Just things to
be aware of.
Conclusion
This has been an overview of the
typical amount of overhead that is incurred when different types of popular
networking interfaces are chosen for conveying 0s and 1s from one point to
another across long distances.
Send
any feedback or questions to:
Richard
Hay
Systems
Engineer
Cell:
(703) 623-5442
rhay@tamos.net